We’ve discussed continental drift and plate tectonics in Proof 22. Plate tectonics. There’s another aspect of plate tectonics that was mentioned in passing there, which deserves some further attention. Proof 22 stated:
But as technology advanced, detailed measurements of the sea floor were made beginning in the late 1940s, including the structures, rock types, and importantly the magnetic properties of the rocks.
That last one, the “magnetic properties”, was the piece of evidence that really cemented continental drift as a real thing.
We pick up the history in 1947, when research expeditions led by American oceanographer Maurice Ewing established the existence of a long ridge running roughly north-south down the middle of the Atlantic Ocean. They also found that the crust beneath the ocean was thinner than that beneath the continents, and that the rocks (below the seafloor sediment) were basalts, rather than the granites predominantly found on continents. There was something peculiar about the Earth’s crust around these mid-ocean ridges. And over the next few years, more ridges were found in other oceans, revealing a network of the structures around the globe. The system of mid-ocean ridges had been discovered, but nobody yet had an explanation for it.
Meanwhile, from 1957, the Russian-American oceanographer Victor Vacquier took World War II surplus aerial magnetometers that had been used to detect submerged submarines from reconnaissance aircraft, and adapted them for use in submarines to examine the magnetic properties of the sea floor. It was well known that basalt contained the mineral magnetite, which is rich in iron and can be strongly magnetised.
What Vacquier found was unexpected and astonishing. In a survey of the Mendocino Fault area off the coast of San Francisco, Vacquier discovered that the sea floor basalt was not uniformly magnetised, but rather showed a distinctive and striking pattern. The magnetism appeared to be relatively constant along north-south lines, but to vary rapidly along the east-west direction, causing “stripes” of magnetism running north-south.[1]

Map of magnetic field measurements on the sea floor near Mendocino Fault, showing strong north-south striping of the magnetic field. (Figure reproduced from [1].)
Follow up observations showed that the stripes were not localised, but extended over large regions of the ocean.[2][3].
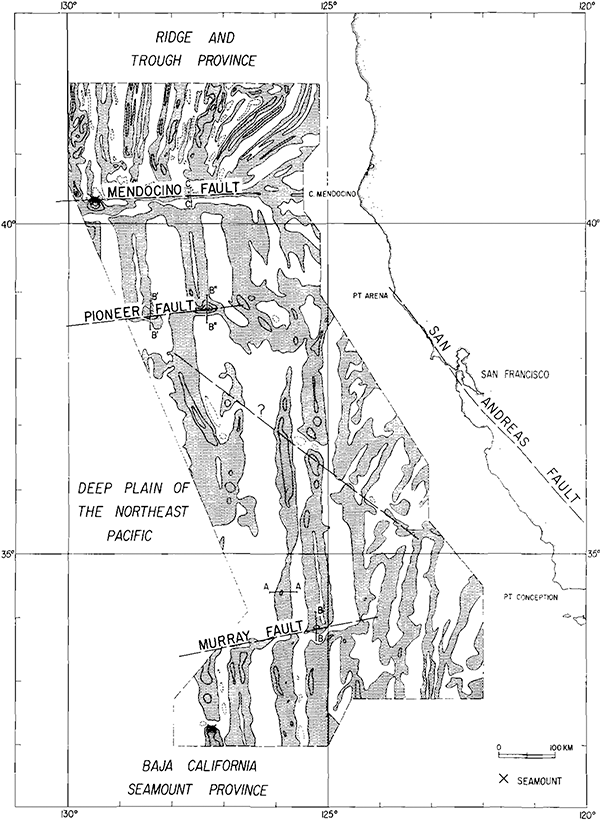
Map of magnetic anomalies on the sea floor off California. Shaded areas are positive magnetic anomaly, unshaded areas are negative. (Figure reproduced from [2].)
In fact, these magnetic “zebra stripes” were present pretty much everywhere on the floor of every ocean. They weren’t always aligned north-south though – it turned out that they were aligned parallel to the mid-ocean ridges. The early discoverers of this odd phenomenon had no explanation for it.
Returning to the mid-ocean ridges, American oceanographer Bruce Heezen wrote a popular article in Scientific American in 1960 that informed readers of the recent discoveries of these enormous submarine geological features.[4] In the article, he speculated that perhaps the ridges were regions of upwelling material from deep within the Earth, and the sea floors were expanding outwards from the ridges. Heezen was not aware of any mechanism for regions of Earth’s crust to disappear, so he suggested that the Earth might slowly be expanding, through the creation of new crust at the mid-ocean ridges.
Although Heezen’s idea of an expanding Earth didn’t take hold, his idea of upwelling and expansion along the mid-ocean ridges was quickly combined with existing proposals (that Heezen had overlooked) that crust could be disappearing along the lines of deep ocean trenches, as parts of the Earth moved together and were subducted downwards. The American geologists Harry Hammond Hess and Robert S. Dietz independently synthesised the ideas into a coherent theory of continental drift, combining the hypotheses of seafloor spreading and ocean trench subduction to conclude that the Earth was not changing size, but rather it was fractured into crustal plates that slowly moved, spreading apart in some places, and colliding and subducting in others.[5][6]
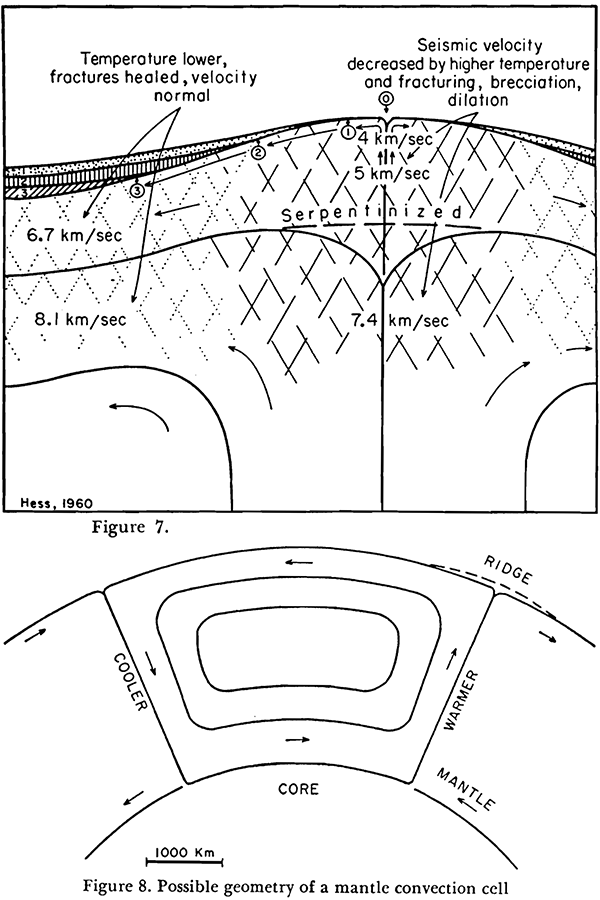
Earliest diagrams of proposed mantle convection cells causing continental drift, with upwelling at mid-ocean ridges causing seafloor spreading, by Harry Hammond Hess. Figure 7 (top) shows the detailed structure of a mid-ocean ridge, with measured seismic velocities (the speed of seismic waves in the rock) in various regions. Hess proposed that the observed lower speeds in the central and upper zones were caused by fracturing of the rock as it deforms during the upwelling, plus higher residual temperature of the upwelled material. Figure 8 (bottom) shows Hess’s proposed mantle convection cells. (Figures reproduced from [6].)
So by the 1960s, most of the observational pieces of this puzzle were in place. However, the unifying theory that would explain it all still required some synthesis, and acceptance of some unestablished hypotheses. This synthesis was again put together independently by two different groups of geologists: the Canadian Lawrence Morley, and the English Ph.D. student Frederick Vine and his supervisor Drummond Matthews. Morley wrote two papers and submitted them to Nature and the Journal of Geophysical Research in 1963, but both journals rejected his work as too speculative. Vine and Matthews thus received publication priority when Nature accepted their paper later in 1963.[7]
The geologists pointed out that if new rock was being created at the mid-ocean ridges and then spreading outwards, then the seafloor rocks should get progressively older the further away they are from the ridges. Each one of the magnetic zebra stripes running parallel to the ridges then corresponds to rocks of the same age. If, they conjectured, the rocks record the direction of the Earth’s magnetic field when they were formed, and for some reason the Earth’s magnetic field reversed direction periodically, that would explain the existence of the magnetic stripes.
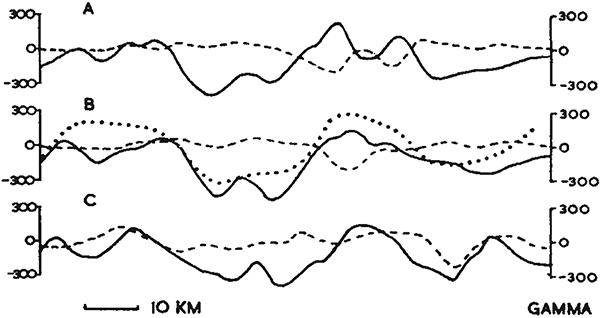
Diagram by Vine and Matthews showing the observed magnetic field strength of the sea floor rocks measured across the Carlsberg Ridge in the Indian Ocean, showing positive and negative regions (solid lines), computed magnetic field strength under conventional (for the time) assumptions (dashed lines), and computed field strength assuming 20 km wide bands in which the Earth’s magnetic field has been reversed. The periodic field reversal matches the observed magnetism much better. (Figure reproduced from [7].)
As with Morley’s rejected papers, this paper was treated with scepticism initially, because it relied on two unproven conjectures: (1) that the rocks maintain magnetism aligned with the Earth;’s magnetic field at the time of solidification and, much more unbelievably, (2) that the Earth’s magnetic field direction reverses periodically. For some geologists, this was too speculative to be believe.
One test of Vine and Matthews’ seafloor spreading hypothesis would be to measure the age of the sea floor using some independent method. If the rocks were found to get progressively older the further away they are from the mid-ocean ridges, then that would be strong evidence in favour of the theory. As it happens, it’s possible to date the age of rocks formed from magma, using a method of radiometric dating known as potassium-argon (K-Ar) dating. Potassium is a fairly common element in rocks, and the isotope potassium-40 is radioactive, with a half-life of 1.248×109 years. Most of the potassium-40 decays to calcium-40 via beta decay (see Proof 29. Neutrino beams for a recap on beta decay), but just over 10% of it decays via electron capture to the inert gas argon-40. Argon is not present in newly solidified rock, but the argon produced by decaying potassium-40 is trapped within the crystal structure. Since the decay rate is known very precisely, we can use the measured ratio of potassium to argon in the rock to determine how long it has been since it formed, for timescales from several million to billions of years.
In the mid-1960s, oceanographers and geologists began drilling cores and taking basalt samples from the sea floor and measuring their ages.[8] And what they found matched the prediction from seafloor spreading: the youngest rocks were at the ridges and became progressively older towards the edges of the oceans.
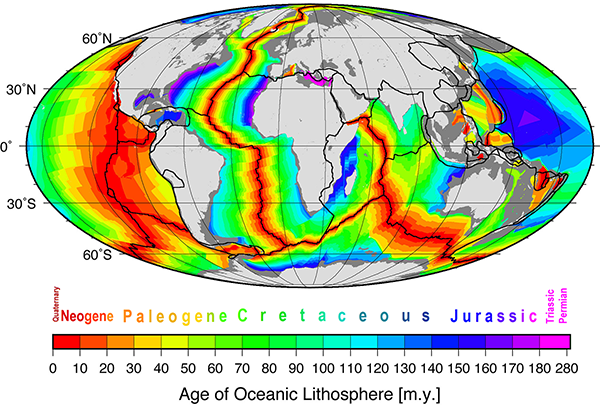
Diagram of the age of oceanic crust. The youngest rocks are red, and found along the mid-ocean ridges. Rocks are progressively older further away from the ridges. (Figure reproduced from [9].)
This was exactly what Vine and Matthews predicted. Belatedly, Morley also received his due credit for coming up with the same idea, and their proposal is now known as the Vine-Matthews-Morley hypothesis. The magnetic striping of the ocean floors is caused by the combination of the spreading of the ocean floors from the mid-ocean ridges, and the periodic reversal of Earth’s magnetic field.
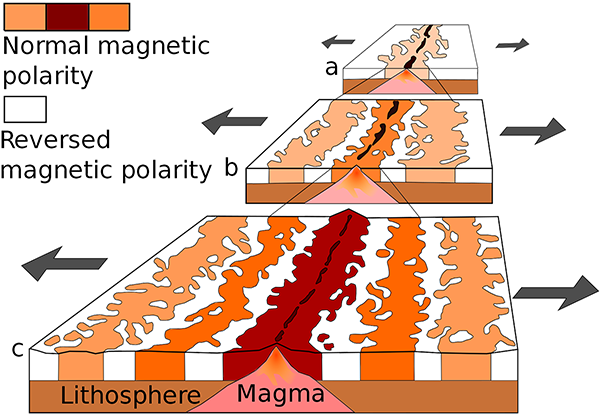
Generation of magnetic striping on the sea floor. As the sea floor spreads, and the Earth’s magnetic field reverses from time to time, stripes of different magnetic polarity are created and spread outwards. (Public domain image by the United States Geological Survey, from Wikimedia Commons.)
Odd reversals of magnetic fields in continental rocks had been noticed since 1906, when the French geologist Bernard Brunhes found that some volcanic rocks were magnetised in the opposite direction to the Earth’s magnetic field. In the 1920s, the Japanese geophysicist Motonori Matuyama noticed that all of the reversed rocks found by Brunhes and others since were older than the early Pleistocene epoch, around 750,000 years ago. He suggested that the Earth’s field may have changed direction around that time, but his proposal was largely ignored.
With the impetus provided by the seafloor spreading idea, geologists began measuring magnetic fields and ages of more rocks, and found that they matched up with the ages of the field reversals implied by the sea floor measurements. Progress was rapid and the geological community turned around and developed and adopted the whole theory of plate tectonics within just a few years. By the end of the 1960s, what had been ridiculed less than a decade earlier was mainstream, brought to that status by the confluence of multiple lines of observational evidence.
It had been established that the Earth’s magnetic field must reverse direction with periods of a few tens of thousands to millions of years. The remaining question was how?
Up until the development of plate tectonics, the origin of the Earth’s magnetic field had been a mystery. Albert Einstein even weighed in, suggesting that it might be caused by an imbalance in electrical charge between electrons and protons. But plate tectonics not only raised the question – it also suggested the answer.
The core of the Earth was known to be mostly metallic (see Proof 43. The Schiehallion experiment). If there are convection currents in the mantle, then heat differentials at the boundary should also cause convection within the core. The convecting metal induces electrical currents, which in turn produce a magnetic field. In short, the core of the Earth is an electrical dynamo. And because the outer core is liquid, the currents are unstable. Modern computer simulations of convection in the Earth’s core readily produce instabilities that act to flip the polarity of the magnetic field at irregular intervals – exactly as observed in the record of magnetic striped sea floor rocks.

Computer simulations of convection currents in the Earth’s core and resulting magnetic field lines. Blue indicates north magnetic polarity, yellow south. The left image indicates Earth in a stable state, with a magnetic north pole at the top and a south at the bottom. The middle image is during an instability, with north and south intermingled and chaotic. The right image is after the unstable period, with the north and south poles now flipped. (Public domain images by NASA, from Wikimedia Commons.)
So we have a fully coherent and self-consistent theory that explains the observations of magnetic striping, along with many other features of the Earth’s geophysics. It involves several interlocking components: convection in the metallic core producing electric currents that generate a magnetic field that is unstable over millions of years and flips polarity at irregular intervals; convection in the mantle producing upwellings of material along mid-ocean ridges, leading to seafloor spreading and continental drift; rocks that record both their age and the direction and strength of the Earth’s magnetic field when they are formed, leading to magnetic striping on the ocean beds.
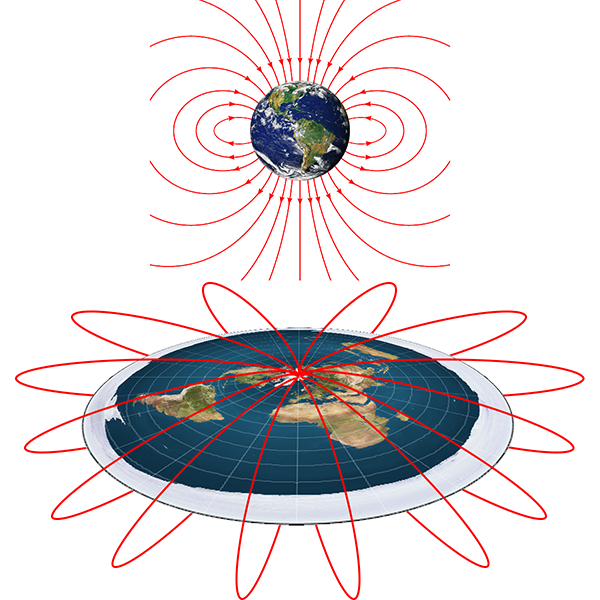
Of course, this only holds together and makes sense on a spherical Earth. We’ve already seen in Proof 8. Earth’s magnetic field, that simply generating the shape of the planet’s magnetic field only works on a spherical Earth, and is an inexplicable mystery on a flat Earth model. It would be even more difficult to explain the irregular reversal of polarity of the magnetic field without a spherical core dynamo system. And plate tectonics just doesn’t work on a flat Earth either (Proof 22. Plate tectonics). Combining the fact that neither of these explanations work on a flat Earth, there is no explanation for the observed magnetic striping of the sea floors either. So magnetic striping provides another proof that the Earth is a globe.
References:
[1] Vacquier, V., Raff, A.D., Warren, R.E. “Horizontal displacements in the floor of the northeastern Pacific Ocean”. Geological Society of America Bulletin, 72(8), p.1251-1258, 1961. https://doi.org/10.1130/0016-7606(1961)72[1251:HDITFO]2.0.CO;2
[2] Mason, R.G. Raff, A.D. “Magnetic survey off the west coast of North America, 32 N. latitude to 42 N. Latitude”. Geological Society of America Bulletin, 72(8), p.1259-1265, 1961. https://doi.org/10.1130/0016-7606(1961)72[1259:MSOTWC]2.0.CO;2
[3] Raff, A.D. Mason, R.G. “Magnetic survey off the west coast of North America, 40 N. latitude to 52 N. Latitude”. Geological Society of America Bulletin, 72(8), p.1267-1270, 1961. https://doi.org/10.1130/0016-7606(1961)72[1267:MSOTWC]2.0.CO;2
[4] Heezen, B.C. “The rift in the ocean floor”. Scientific American, 203(4), p.98-114, 1960. https://www.jstor.org/stable/24940661
[5] Dietz, R.S. “Continent and ocean basin evolution by spreading of the sea floor”. Nature, 190(4779), p.854-857, 1961. https://doi.org/10.1038%2F190854a0
[6] Hess, H.H. “History of Ocean Basins: Geological Society of America Bulletin”. Petrologic Studies: A Volume to Honour AF Buddington, p.559-620, 1962. https://doi.org/10.1130/Petrologic.1962.599
[7] Vine, F.J. Matthews, D.H. “Magnetic anomalies over oceanic ridges”. Nature, 199(4897), p.947-949, 1963. https://doi.org/10.1038/199947a0
[8] Orowan, E., Ewing, M., Le Pichon, X. Langseth, M.G. “Age of the ocean floor”. Science, 154(3747), p.413-416, 1966. https://doi.org/10.1126/science.154.3747.413
[9] Müller, R.D., Sdrolias, M., Gaina, C. Roest, W.R. “Age, spreading rates, and spreading asymmetry of the world’s ocean crust”. Geochemistry, Geophysics, Geosystems, 9(4), 2008. https://doi.org/10.1029/2007GC001743



















{kind=link}
{kind=link}
{kind=link}